Application of Cofactor Expansion
Last updated on January 9, 2023 am
Application of Cofactor Expansion
Laplace expansion, also known as cofactor expansion or first Laplace theorems on determinants, is a recursive way to calculate determinant of a square matrix.
But it’s also clear that for a generic matrix, using cofactor expansion is much slower than using LU decomposition. So, what’s the real advantage of Laplace expansion? In what kind of situation can we use this method?
To give a quick answer: when a matrix comes with many zeros.
Additionally, when a matrix constitutes some variables.
From the Definition
Besides expressing the theorem with sigma notaion (Σ), there is also another equivalent form accroding to Linear Algebra for Computational Sciences and Engineering:
The determinant of a matrix is equal to scalar product of a row (column) vector by the corresponding vector of cofactors.
I rather like this definition.
Being Lazy
We can note that each term of summation is the product of a matrix entry and its cofactor.
So, it’s clear that if any of the two factors is zero, this term will be zero and we can calculate one thing less.
Although an entry’s cofactor needs some complex arithmetic, zero entries in a matrix can be easily determined.
Handling Some Uncertainty
Thinking from the opposite, lower-upper decomposition is probably not completely applicable to a matrix with some variables. In this case, we cannot determine an entry is a pivot or not if it contain some unknowns.
At this point, cofactor expansion can help, but this is not the focus of this post.
Real Stuff
Let’s realize it in Python and check what outcome exactly could be when there are some zeros in a matrix.
Reinvent the Wheel
Firstly, we need to gengerate a square matrix randomly.
Generate a Matrix
1 | |
In Line 8, int(random.uniform(lower, upper)) returns a value in continuous uniform distribution. Bounds lower and upper are not included since there is a type cast with int().
Note that 0 is also in the bounds, so from Line 9 to Line 14 we are handling this problem, trying to make sure that the number of zeros in the returned matrix is exactly the same as zeros we passed in. This may demolish the idea of uniform distribution, but not impact the purpose of this demonstration.
1 | |
Output (probably):
1 | |
1 | |
Realization
To calculate determinant, according to cofactor expansion, we need cofactor. As for cofactor, we need complement minor, which comes from complement submatrix.
1 | |
Complement minor is exactly the determinant of complement submatrix, so the sequence of function call expands in a recursive manner.
In Line 7, we selected a random row to apply first Laplace theorem. Note that all rows and columns begin with 0 index and end with n-1.
Function of complement submatrix is a little bit fancy. Essentially, it’s just a bunch of list slicing.
Benchmarking
Cofactors are useful when matrices have many zeros.
Gilbert Strang, Introduction to Linear Algebra
To test its convenience, we can simply measure running time it used.
1 | |
Output:
1 | |
We can see that with the number of zeros in matrix increase, time needed to calculate det() is getting less rapidly.
Here is a result in terms of a 10 by 10 matrix with number of zeros ranging from 0 to 45, plotted with matplotlib.pyplot (for full script, please refer to Appendix):
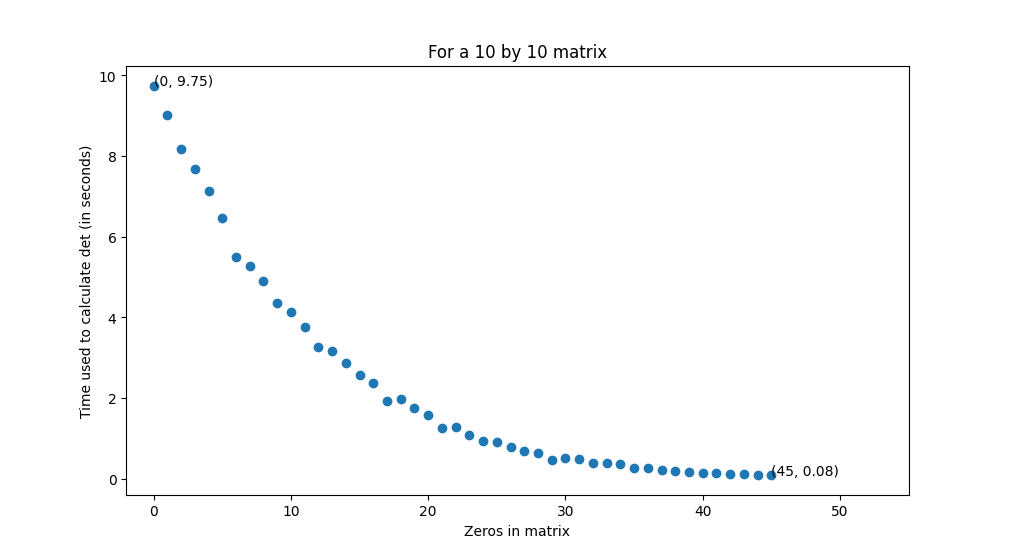
From Figure 1 we can see that only a few zeros can reduce calculation time to a large extend.
Here we just pick a random row to calculate det(), and if we chose a row (column) with the most zeros, the time might have been reduced even faster.
Remark
When learning linear algebra and going through the textbook, tons of jargons come in, with many definitions, theorems, proofs and properties. But as a student major in computer science, I really want to know what’s the usage of them, in what circumstances can we use them. I care more about real-life application and realization.
In terms of cofactor expansion, to calculate determinant recursively is a fun topic, but not a very efficient manner, as recursion always occupy a large amount of memory and hard to optimize.
So does almost every industrial implementation of determinant come from LU decomposition.
However, Laplace expansion is not meaningless, and that’s why I wrote this post.
References
- Linear Algebra for Computational Sciences and Engineering, 2nd Edition, Ferrante Neri, Springer Cham, 2019.
- Introduction to Linear Algebra, 5th Edition, Gilbert Strang, Wellesley-Cambridge Press, 2016.
- Cofactor Expansions
- Laplace expansion - Wikipedia
- Applications of minors and cofactors
- LU decomposition - Wikipedia
- LU Factorization
- Mutable Sequence Types - Built-in Types - Python 3.11.1 documentation
- numpy.linalg.det — NumPy v1.24 Manual
Appendix: Full Script
1 | |